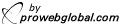Joy Buolamwini estaba investigando en el MIT (Massachusetts Institute of Technology) sobre el reconocimiento facial cuando comenzó a notar algo extraño. Cada vez que se sentaba frente a la cámara frontal de un sistema, no reconocía su rostro, incluso después de haber funcionado con sus amigos de piel más clara. Pero, cuando se puso una simple máscara blanca, la animación de seguimiento de rostro de repente iluminó la pantalla.
Sospechando un problema más generalizado, llevó a cabo un estudio sobre los sistemas de reconocimiento facial de Microsoft, IBM y Face ++, una startup china que ha recaudado más de 500 mdd de inversionistas. Buolamwini probó los sistemas con 1,000 caras distintas, pidiendo que diferenciaran cada una entre hombre y mujer. Las tres compañías lo hicieron espectacularmente bien al discernir entre caras blancas, y hombres en particular. Pero, cuando se trataba de mujeres de piel oscura, los resultados eran sombríos: hubo un 34% más de errores en las mujeres de piel oscura que en los hombres de piel clara; según los hallazgos que Buolamwini presentó el sábado 24 de febrero en la Conferencia sobre Equidad, Rendición de Cuentas y Transparencia en Nueva York.

A medida que los tonos de piel de las mujeres se volvían más oscuras, las probabilidades de que los algoritmos predijeran su género correctamente eran como “lanzar una moneda”. Con las mujeres de piel más oscura, los sistemas de detección de rostros confundieron el género casi la mitad de las veces.
El proyecto de Buolamwini, que se convirtió en la base de su tesis del MIT, muestra que las preocupaciones sobre el sesgo están agregando una nueva dimensión a la ansiedad general en torno a la inteligencia artificial (IA). Si bien se ha escrito mucho sobre las formas en las que el machine learning reemplazará labores humanas, el público ha prestado menos atención a las consecuencias de los conjuntos de datos sesgados.
¿Qué sucede, por ejemplo, cuando los ingenieros de software entrenan sus algoritmos de reconocimiento facial principalmente con imágenes de hombres blancos? La investigación de Buolamwini mostró que el algoritmo mismo se vuelve prejuicioso.

Otro ejemplo salió a la luz en 2016, cuando Microsoft lanzó su chatbot de IA en Twitter. Los ingenieros programaron el bot para aprender el comportamiento humano al interactuar con otros usuarios de Twitter. Después de solo 16 horas, la cuenta fue cerrada porque sus tweets se habían convertido en un hilo de mensajes sexistas pro-Hitler. Los expertos más tarde dijeron que, Microsoft había enseñado a Tay a imitar el comportamiento, pero no lo entrenaron lo suficiente para saber qué comportamiento era el adecuado.
Suranga Chandratillake, un importante capitalista de riesgo en Balderton Capital en Londres, Reino Unido, dice que el sesgo en la IA es un tema tan preocupante como el de la destrucción de empleos. “No soy negativo acerca del impacto en el trabajo”, dice. El problema más grande es construir sistemas, alimentados por una inteligencia artificial que tome datos históricos para emitir juicios. “Los datos históricos podrían estar totalmente sesgados”, dice Chandratillake desde su oficina en Kings Cross, que está justo en la calle de la sede de DeepMind, la compañía líder de inteligencia artificial de Google.
“En promedio, la gente aprueba hipotecas para hombres o personas que son blancas, o de cierta ciudad”. Cuando el poder de emitir ese juicio se otorga a una máquina, la máquina “codifica ese sesgo”.
Hasta ahora, los ejemplos de sesgos causados por los algoritmos han parecido triviales, pero en conjunto, pueden tener un impacto, especialmente con tantas compañías que compiten por incorporar inteligencia artificial a sus aplicaciones y servicios. (Las menciones de “IA” en los anuncios de resultados financieros se han disparado en el último año, según CB Insights, incluso de compañías poco probables como Procter & Gamble o Bed Bath & Beyond).
En los últimos meses, varios investigadores han señalado cómo incluso el Traductor de Google ha mostrado signos de sexismo, sugiriendo automáticamente palabras como “él” para los trabajos dominados por hombres y viceversa, cuando se traduce desde un idioma de género neutro como el turco. Camelia Boban, una desarrolladora de software en Italia, también notó el 4 de febrero que Google Translate no reconocía el término femenino para “programador” en italiano, que es programmatrice. (Ella dijo en un correo electrónico reciente a Forbes que el problema ya se ha corregido, pero el traductor nos muestra otra cosa).
Tales ejemplos pueden sonar sorprendentes cuando se espera que el software sea lógico y objetivo. “La gente cree que las máquinas son racionales”, dice Chandratillake. “Terminas sin darte cuenta de que en realidad, lo que debería ser meritocrático, no lo es en absoluto. Es solo una codificación de algo que no estaba desde el inicio”.
Cuando los humanos toman decisiones importantes sobre la contratación o la concesión de un préstamo bancario, es más probable que se les pregunte sobre su razonamiento. Hay menos motivos para cuestionar a la IA debido a “este barniz de nueva tecnología innovadora”, dice, “pero está destinada a repetir los errores del pasado”.
Hoy en día, los ingenieros están demasiado concentrados en construir algoritmos para resolver problemas complejos, en lugar de construir un algoritmo para monitorear e informar cómo está funcionando el primer algoritmo, una especie de perro guardián algorítmico. “Hoy, la forma en que se configura una gran cantidad de inteligencia artificial es básicamente una caja negra”, agrega. “Las redes neuronales no son buenas para explicar por qué tomaron una decisión”.
Buolamwini de MIT señala la falta de diversidad en imágenes y datos utilizados para entrenar algoritmos. Afortunadamente, este es un problema en el que se puede trabajar.
Después de que Buolamwini, del MIT, envió los resultados de su estudio a Microsoft, IBM y Face ++; IBM respondió replicando su investigación internamente, y lanzando una nueva Interfaz de programación de aplicaciones (API por sus siglas en inglés), de acuerdo con un participante de la conferencia que asistió a su presentación. El sistema actualizado, ahora clasifica a las mujeres de piel oscura con una tasa de éxito del 96.5%.
Actualidad Laboral / Con información de Forbes México